Humanoid robot data · 8 June 2026
What NVIDIA Isaac GR00T Means for Humanoid Robot Training Data
NVIDIA Isaac GR00T is NVIDIA's attempt to make humanoid development look less like a one-off lab project and more like a repeatable stack. The platform connects robot foundation models, data pipelines, simulation, middleware, runtime libraries, and Jetson Thor hardware for real-time inference and control.
The useful story is not only "NVIDIA has a humanoid model." It is that GR00T treats data as a whole system: real captured demonstrations, synthetic trajectories, internet-scale video, language instructions, onboard camera streams, and robot proprioceptive state all have different jobs. That matters for anyone buying, selling, or preparing humanoid robot training data.

Source: NVIDIA Isaac GR00T repository.
If you are new to the category, start with our broader guide to humanoid robot training data. This article looks at GR00T as a signal for the next layer of dataset diligence.
What Isaac GR00T is
At the platform level, Isaac GR00T covers the workflow from data capture to robot deployment. The stack includes open data and data pipelines, an open robot foundation model, simulation frameworks built on NVIDIA Omniverse and Cosmos, middleware, CUDA-X runtime libraries, and Jetson Thor for deployment.
The model family focuses on generalized humanoid reasoning and skills. Its public materials frame GR00T as a cross-embodiment model that can take multimodal input, including language and images, then adapt through post-training for specific robot bodies, tasks, and environments.
Watch the short overview before the data breakdown. It shows why perception, instruction following, action generation, and simulation do not sit in separate boxes. They are parts of the same training loop.
Isaac GR00T N1 overview: a short visual primer before the data discussion.
The data mix matters more than the slogan
The GR00T page gets most interesting when it stops being about one model and starts being about the training mix: internet-scale human video for broad world knowledge, real-world teleoperation for physical grounding, and synthetic data to scale learning without collecting every edge case by hand.
Each part of that mix fills a different gap.
Internet-scale video can help a model understand objects, human actions, task semantics, and visual context. But video alone usually does not contain the robot's joint state, action commands, contact timing, control constraints, or failure labels.
Teleoperation demonstrations can add the missing physical grounding. A good teleoperation dataset can show what the robot saw, what command it was trying to follow, how the robot state changed, which action was sent, and whether the task worked.
Synthetic data can then widen coverage across object placements, environments, camera views, and task variants. The hard part is not simply generating more episodes. The hard part is keeping synthetic trajectories physically plausible and useful for the target embodiment.
So the buyer question gets sharper: does this dataset preserve the relationship between scene, instruction, body state, action, contact, and outcome?
Inputs and outputs show what buyers should ask for
GR00T's input/output shape is a useful buyer checklist. The model consumes video sequences from onboard cameras, natural language commands, and the robot's proprioceptive state, such as joint positions. It outputs action chunks: predictive sequences of relative joint motions.
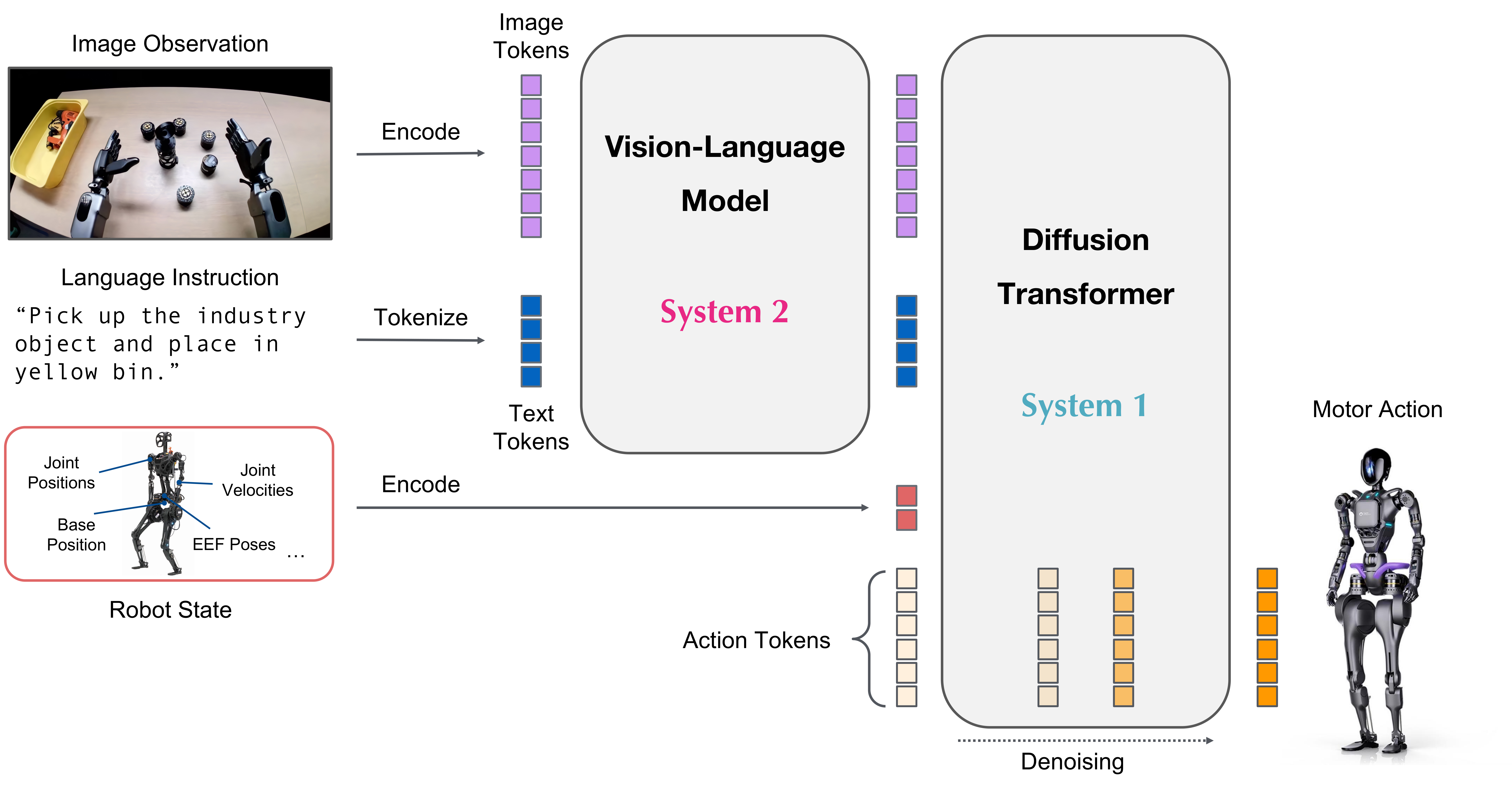
{kind=link}
That turns the diagram into something practical. If a team wants data for humanoid policy learning or post-training, a folder of videos is rarely enough. Buyers should ask whether the dataset includes:
- Camera streams from the robot's actual viewpoint, not only external footage.
- Natural language instructions or task labels tied to each episode.
- Synchronized robot state, including joint positions and other relevant proprioceptive signals.
- Action records, control rates, coordinate frames, and episode boundaries.
- Outcomes, failures, retries, interventions, and reset conditions.
- Embodiment details: robot body, hands, sensors, joint limits, calibration, and retargeting steps.
For a fuller buyer checklist, read How to Evaluate Humanoid Robot Training Data Before You Buy. The short version for GR00T is simple: if the model consumes state, language, and video, a useful dataset should keep those signals together.
Teleoperation becomes a premium data source
Isaac-Teleop sits in the GR00T workflow because demonstrations matter. Teleoperation data can be expensive, but it often contains more learning signal than passive footage: intent, correction, recovery, and task strategy.
For buyers, the key is to understand the capture setup. A teleoperation dataset should say who or what controlled the robot, what interface was used, whether the operator saw first-person or third-person views, what latency was present, and how success was judged.
For sellers, the lesson is simple. Do not describe your asset only as "robot videos" or "teleop logs." Package it as demonstrations:
- Task instruction.
- Operator setup.
- Robot and sensor configuration.
- Synchronized observations, state, and actions.
- Success, failure, and recovery labels.
- Known limitations and unsafe or excluded cases.
That context can make the difference between a dataset that looks interesting and one a robotics team can actually evaluate.
Synthetic data still needs provenance
GR00T-Dreams belongs in the article at this point because it is about the data bottleneck. The workflow uses world models and simulation to expand training coverage, so a team can explore more tasks, environments, and object placements than it could capture manually.
GR00T-Dreams walkthrough: synthetic data and world-model-driven robot training.
That does not make synthetic data automatically low-quality or automatically safe. It changes the diligence questions.
Buyers should ask how synthetic episodes were generated, what real demonstrations or environments seeded them, which simulator or world model was used, and how the synthetic data was validated. They should also ask whether the synthetic distribution matches the deployment target or mostly shows idealized scenes.
Sellers should document synthetic data with the same seriousness as real captured data. Include generation prompts or task specifications where possible, simulator settings, robot constraints, asset sources, validation checks, and any filtering process. If synthetic data was mixed with real data, explain the mixture instead of hiding it.
Cross-embodiment does not remove embodiment fit
GR00T's cross-embodiment framing is important, but it should not be read as "any humanoid data works for any humanoid robot."
Embodiment still matters. A robot with different hands, joint limits, camera placement, payload, balance behaviour, or control frequency may need retargeting, filtering, or new demonstrations. Data from another robot can still be valuable for perception, task sequencing, evaluation, or pretraining, but buyers should not treat cross-embodiment as a shortcut around technical diligence.
The practical question is: what must transfer directly, and what can be adapted?
For policy learning, that usually means checking the robot body, sensors, coordinate frames, action space, timing, and task distribution before discussing price. For sellers, it means being clear about the embodiment rather than trying to make the dataset sound universal.
Early access is not the same as production certainty
Isaac GR00T 1.7 is still Early Access. Developers can use pretrained model weights and reference code, then fine-tune or run inference with custom robot data or demonstrations, but NVIDIA positions this as experimentation, prototyping, and research rather than production deployment with commercial support.
That caveat matters. If a team is building around GR00T today, the data strategy should not depend on a single model version or a single vendor workflow. Strong datasets should remain useful even if the model, inference stack, or deployment hardware changes.
That means clean formats, clear rights, documented capture, reusable annotations, and enough raw signal to support future training runs. A dataset prepared only for one demo may be hard to reuse. A dataset prepared as a durable robotics asset has a longer commercial life.
What this means for the data market
Isaac GR00T is a model and platform story, but it is also a market signal. Humanoid robotics data is becoming more structured. Buyers will increasingly look for packages that combine video, language, robot state, actions, outcomes, and rights clarity. Sellers with well-documented teleoperation, motion, simulation, or interaction datasets will be easier to diligence than sellers with impressive footage and vague metadata.
The useful takeaway is not that every dataset must look exactly like NVIDIA's stack. It is that humanoid robot training data is moving toward embodied context. The more a dataset preserves how a robot perceived, moved, touched, failed, recovered, and followed an instruction, the easier it is to judge its value.
If you need data for humanoid robot learning, use the buyer request form. If you have teleoperation logs, robot demonstrations, simulation data, motion data, or other robotics datasets to list or license, use the seller submission form.