Humanoid robot data · 9 June 2026
What NVIDIA GRAIL Means for Humanoid Loco-Manipulation Data
NVIDIA Research's GRAIL is a useful signal for where humanoid robot training data is going. The NVIDIA and UCLA project generates humanoid loco-manipulation demonstrations from 3D assets and video priors, then reports transfer to a real Unitree G1 for object pick-up and stair-climbing.
The market lesson is sharper than "synthetic demos are getting better." GRAIL shows that generated humanoid data becomes more credible when it has provenance before pixels: known assets, known geometry, known camera parameters, known scale, known robot assumptions, and evidence that the resulting trajectories can survive contact with a real robot.
GRAIL teaser video. Source: NVIDIA Research GRAIL project page.
If you are new to the category, start with our broader guide to humanoid robot training data. This article looks at GRAIL as a data-market signal: what it says about synthetic demonstrations, 3D asset provenance, embodiment fit, and buyer diligence.
Why GRAIL is a data story
Humanoid loco-manipulation is hard because the robot has to move through space and manipulate objects at the same time. Picking up an object from a table is not only a grasping problem. The robot must approach, place its feet, align the torso, move the arms, make contact, lift without losing balance, and recover into a useful posture.
Collecting that kind of data through teleoperation or motion capture is expensive. Every new object, scene, staircase, chair, or awkward placement can require another physical setup. GRAIL is interesting because it moves much of that variation into a virtual generation pipeline while still preserving the information a robot needs: body motion, object motion, scene geometry, scale, and action targets.
The GRAIL project page says the pipeline produces more than 20,000 sequences across pick-up, whole-body manipulation, sitting, and terrain traversal. That scale is useful context, but the stronger lesson is the structure behind the scale.
The pipeline starts before the video
Many robotics teams want to use human videos as training signal. The problem is that ordinary videos are missing the details robots need. They rarely include accurate 3D object geometry, camera calibration, scene depth, contact timing, robot-compatible body proportions, or action labels.
GRAIL approaches the problem from the opposite direction. It first assembles a fully specified 3D configuration. The system knows the asset, scene, camera, metric scale, and character setup. A video foundation model then generates a reference interaction video from that controlled starting point. After that, GRAIL reconstructs coherent 4D human-object interaction trajectories and retargets them to a humanoid robot.
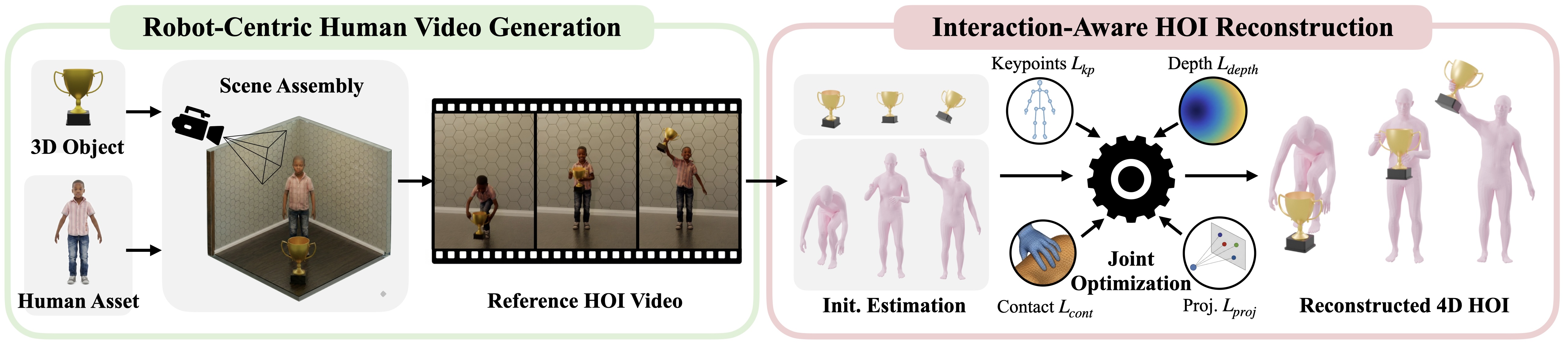
Asset-conditioned 4D human-object interaction generation. Source: NVIDIA Research GRAIL project page.
That order is important. The video prior helps produce natural-looking interaction, but the known 3D setup keeps the result anchored to a scene that can be reconstructed, retargeted, and used for robot training.
For buyers, this is a useful distinction. "Synthetic video" is not a complete dataset category. A synthetic episode is much more valuable when the seller can explain what was known before generation, what was inferred afterward, and what validation was used before the data was accepted.
Object manipulation and locomotion belong together
GRAIL covers two capability blocks: object-centric interaction and scene-aware locomotion.
The object side includes table pick-up, ground pick-up, and whole-body manipulation. These tasks test more than end-effector control. Ground pick-up may require squatting, reaching, grasping, and standing back up. Larger objects may require carrying, pushing, repositioning, or changing grip while the feet and torso stay balanced.
Table pick-up example. Source: NVIDIA Research GRAIL project page.
Stair traversal example. Source: NVIDIA Research GRAIL project page.
The locomotion side includes sitting, curbs, slopes, and stairs. These are not decoration around the manipulation tasks. They are part of the reason humanoid data needs to be specialized. A humanoid robot's usefulness in human spaces depends on body alignment, terrain-conditioned foot placement, balance recovery, and the ability to keep perception and planning stable while the body changes posture.
That is why loco-manipulation data should not be evaluated as separate piles of "walking clips" and "grasping clips." The valuable signal is often in the transition between them: approach, align, reach, contact, lift, carry, sit, step, recover.
Known 3D context is a form of provenance
In dataset diligence, provenance usually means who collected the data, how it was captured, and what rights attach to it. GRAIL adds another useful layer: generation provenance.
A GRAIL-like synthetic dataset should be able to describe:
- Which 3D assets were used, where they came from, and whether their rights permit model training.
- How object scale, mass assumptions, placement, and scene geometry were defined.
- Which camera parameters and viewpoints were used.
- How the character or motion source was fitted to the target robot body.
- What video generation model or prior influenced the interaction.
- How 4D trajectories were reconstructed, filtered, and retargeted.
- What validation was run before the data was used for policy learning.
This matters commercially because synthetic robotics data can look plausible while still being weak training material. A buyer needs to know whether the episode preserves the relationships between scene, object, body, contact, timing, and outcome. If those relationships are undocumented, the dataset may be hard to trust even if the clips look clean.
Licensing belongs in that same conversation. For synthetic humanoid data, rights questions can touch meshes, textures, scanned spaces, motion sources, generated videos, reconstructed trajectories, and downstream policy-training rights. A seller does not need to make every dataset universal, but they do need to make the permitted uses legible.
Retargeting turns media into robot data
The output of a synthetic video workflow is not automatically robot training data. GRAIL's method includes reconstruction and retargeting steps that turn recovered human-object interaction into robot-compatible motion and actions.
Task-general tracking and policy adaptation pipeline. Source: NVIDIA Research GRAIL project page.
This is where embodiment fit comes back. GRAIL's reported deployment targets a Unitree G1. Data retargeted for one humanoid body may still help another robot, but hands, joint limits, camera placement, action space, payload, controller interface, and balance behavior all affect how much adaptation is needed.
That is why buyers should ask for the retargeting assumptions, not only the final clips. If a dataset claims to support humanoid policy learning, it should explain the target robot body, coordinate frames, action representation, control frequency, and any filtering used when a motion could not be made physically plausible.
Sim-to-real is the proof section
The GRAIL page reports real Unitree G1 deployment for object pick-up and stair-climbing. It also describes egocentric RGB policy training from rendered views and early GR00T fine-tuning experiments using a mixture of 95% GRAIL data and 5% teleoperation data.
Real-world deployment examples reported by the GRAIL project. Source: NVIDIA Research GRAIL project page.
That is the right place to focus. Synthetic data should not be judged only by whether it can generate many episodes. It should be judged by what happens when a policy trained with that data meets real sensors, real floors, real objects, latency, imperfect actuation, and small perception errors.
For a robotics data buyer, sim-to-real evidence can include:
- Real robot deployment videos tied to specific training data mixtures.
- Success rates, failure modes, and task definitions.
- Details about the target robot, controller, sensors, and environment.
- Ablations showing what changed when synthetic data was added or removed.
- Examples of where the synthetic data did not transfer cleanly.
The last point is important. A serious dataset should not pretend every generated episode is useful. Filtering, rejection, and known failure cases are part of the product.
What this means for teams buying data
GRAIL sharpens the buyer checklist for synthetic humanoid data. Volume still matters, but it is not the first question. The first question is whether the data can be mapped into the robot learning workflow without losing the physical context.
Ask whether the dataset includes robot-compatible trajectories, not only videos. Ask how human-object interaction was reconstructed. Ask whether the object and scene assets are available, documented, and rights-cleared. Ask what is synchronized with what: camera frames, object pose, body pose, actions, outcomes, and task labels.
Then ask about embodiment fit. Data prepared for one humanoid can still be valuable for perception, task sequencing, evaluation, or pretraining, but it is not automatically a policy-training fit for another body. Buyers should understand which parts transfer directly and which parts require retargeting, filtering, or new demonstrations.
For a practical buyer checklist, read How to Evaluate Humanoid Robot Training Data Before You Buy. The same basics still apply here: sample files, clear provenance, embodiment fit, and proof that the data can be loaded without guesswork.
What this means for teams selling data
For sellers, GRAIL is a packaging lesson. If you are offering simulation data, generated demonstrations, motion data, or retargeted trajectories, do not sell it as a folder of files. Sell it as a documented training asset.
The strongest packages will make the generation chain clear:
- Source assets and rights.
- Task specifications and success criteria.
- Robot body and retargeting assumptions.
- Modalities included in each episode.
- Quality filters, rejected cases, and known gaps.
- Example loaders and schema documentation.
- Evidence that the data helped a real policy, benchmark, or evaluation.
There is also a positioning lesson. "Synthetic" should not be treated as a cheap substitute for real robot data. The more useful framing is coverage. Synthetic data can expand object variety, environment variety, terrain variety, and edge-case variety, while a smaller amount of real teleoperation or deployment data can keep the training loop grounded.
That is close to the broader signal in NVIDIA Isaac GR00T: humanoid learning stacks are becoming mixtures of real demonstrations, synthetic trajectories, video priors, simulation, language, and robot state. The market will reward datasets that explain their role in that mixture.
The open questions buyers should keep asking
GRAIL is promising, but it should not make buyers careless. The hard questions are still hard.
How accurate are the contacts? How often do generated motions violate dynamics or rely on impossible balance? How much task diversity is real diversity rather than repeated templates with small visual changes? Are the assets licensed for commercial model training? Does the target robot have the same sensing and control assumptions? What failure modes appear when the policy leaves the generated distribution?
Those questions are not criticisms of GRAIL specifically. They are the normal diligence questions for any synthetic humanoid training dataset. Good sellers should be ready for them. Good buyers should ask before negotiating around price or exclusivity.
The market signal
GRAIL points toward a more structured future for humanoid robot data. The next valuable datasets will not be judged only by how many hours of footage they contain. They will be judged by how well they preserve the whole interaction: the scene, body, object, camera, motion, contact, action, and result.
That is good for the market. Buyers get a clearer way to compare datasets. Sellers with strong provenance and documentation can stand out. Synthetic data providers can compete on transfer evidence and dataset usability, not just generation volume.
Humanoids Data helps teams find and evaluate humanoid robotics datasets across motion, vision, teleoperation, simulation, and interaction data. If you need data for humanoid robot learning, use the buyer request form. If you have robotics data to list or license, use the seller submission form.