Humanoid robot data · 11 June 2026
Humanoid Robot Data Collection Equipment: What Buyers Should Evaluate
Humanoid robot data is not only defined by the task. It is defined by the equipment stack: cameras, depth sensors, robot state, operator controls, force signals, tactile sensors, motion capture, timing, calibration, and the software that keeps all of it aligned.
That matters because two datasets can both be called "humanoid teleoperation data" while being very different products. One might contain front-camera video and a task label. Another might contain synchronized egocentric video, wrist cameras, joint states, action commands, hand poses, tactile signals, force data, operator intent, failure labels, and clean episode boundaries. The second dataset can support much deeper robot learning, but only if the equipment was calibrated, documented, and legally usable.
If you are new to the category, start with the broader guide to humanoid robot training data. This article looks one layer lower: what each collection setup actually captures, why it changes dataset value, and what buyers should ask before comparing price per hour or price per episode.
Start with the rig, not the headline volume
Volume is easy to market. Equipment quality is harder to fake.
A humanoid dataset's collection stack decides which questions the data can answer. Did the robot see the object from its own viewpoint, or only from an external camera? Were the actions recorded, or only the resulting motion? Did the hand touch, slip, squeeze, or collide? Was the operator using an XR headset, a motion capture suit, a haptic device, leader arms, keyboard control, scripted simulation, or autonomous execution? Are failures and interventions preserved, or were they trimmed away?
The useful buyer question is not "how many hours?" It is: what was captured at each timestep, and can those streams be replayed together?
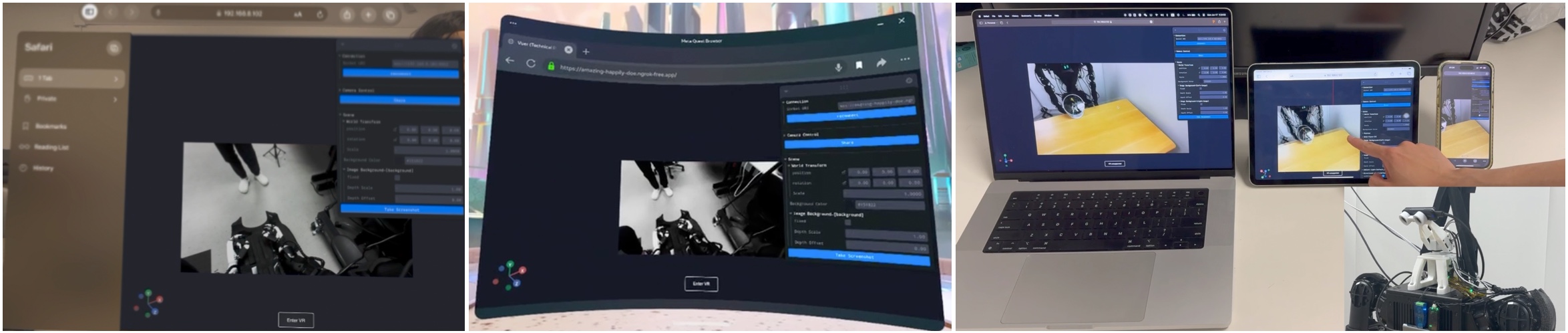
Teleoperation equipment now often includes XR headsets, hand tracking, and live robot-view feedback, not only joysticks. Source: Open-TeleVision paper.
That is why NVIDIA Isaac GR00T's data stack is a useful reference point even for teams not using NVIDIA's model. It makes the buyer checklist visible: camera streams, language, robot state, actions, and embodiment details belong together.
The equipment map
Most humanoid data collection systems mix several rig types:
- On-robot sensors: head cameras, wrist cameras, depth cameras, LiDAR, IMUs, joint encoders, tactile hands, and force sensors.
- Human operator interfaces: XR headsets, hand tracking, gloves, leader arms, haptic devices, space mice, joysticks, keyboards, or scripted task controls.
- Motion capture and body tracking: optical marker systems, IMU suits, hand pose trackers, external RGB pose estimation, and retargeting software.
- Environment sensors: external RGB-D cameras, motion capture cameras, object trackers, pressure carpets, fiducials, and calibrated scene assets.
- Logging and replay systems: synchronized timestamps, schemas, episode boundaries, file formats, calibration metadata, and sample loaders.
The equipment does not need to be maximal. It needs to be right for the learning use case. A simple, well-synchronized wrist-camera and state/action dataset can be more useful than a sensor-heavy archive with unclear timing.
On-robot sensors define the robot's view
On-robot sensing is the base layer. It usually includes head cameras, chest cameras, wrist cameras, depth cameras, inertial sensors, joint encoders, motor state, and sometimes microphones, force sensors, or tactile hands.
This is the most important perspective for policy learning because it records what the robot actually observed while acting. External footage can make a demo look clear to humans. Egocentric robot footage is what the deployed robot will see.
For buyers, the diligence questions are concrete:
- Which cameras were mounted where?
- Were RGB, depth, and robot state synchronized to the same episode timeline?
- Are camera intrinsics, extrinsics, timestamps, and dropped-frame rates included?
- Are joint positions, velocities, torques, and action commands recorded separately?
- Does the dataset include the robot body, hand model, joint limits, control frequency, and coordinate frames?
AgiBot World and AgiBot World 2026 are good public examples of rich on-robot capture. The Colosseo paper reports more than one million trajectories across 217 tasks, 87 skills, and 106 scenes, collected with humanoid platforms that combine mobile bases, dual arms, dexterous hands, visual-tactile sensing, multiple camera views, depth, calibration, proprioception, and language or substep annotations. The public 2026 dataset card describes LeRobot-style metadata, Parquet state/action records, per-camera MP4 videos, and task annotations, with a CC BY-NC-SA license caveat.
AgiBot World is a useful reference for hardware-rich humanoid collection: robot embodiments, multiple camera views, state/action records, annotations, and public packaging. Source: AgiBot World repository.
Humanoid Everyday shows a different version of the same pattern. Its public materials describe Unitree G1 and H1 robots, Intel RealSense RGB-D cameras, Livox LiDAR, tactile or hand-pressure sensors on the G1 setup, IMU, joint poses, actions, odometry, operator hand and head actions, and natural-language annotations at 30 Hz. The paper reports sub-millisecond synchronization. That synchronization claim is exactly the sort of equipment detail buyers should look for, because a camera stream and a joint command are only useful together if they agree on time.
XR teleoperation turns human skill into demonstrations
Teleoperation is where many valuable humanoid datasets begin. A human operator controls the robot or a simulated robot, and the system records the task instruction, observations, robot state, actions, and outcome.
The equipment can look very different across projects:
- VR headsets and hand controllers for immersive whole-body control.
- Apple Vision Pro-style interfaces for hand and body tracking.
- Motion capture suits or optical marker systems for whole-body retargeting.
- Haptic devices or leader arms for precise manipulation.
- Keyboard, joystick, or space mouse controls for simulation and simpler tasks.
Fourier ActionNet, Humanoid Everyday, Unitree's UnifoLM-WBT collection, Open-TeleVision, and NVIDIA's GR00T teleoperation materials all point in the same direction: the operator interface is part of the dataset's provenance. It affects latency, viewpoint, hand fidelity, body posture, error patterns, and how natural the demonstrations are.
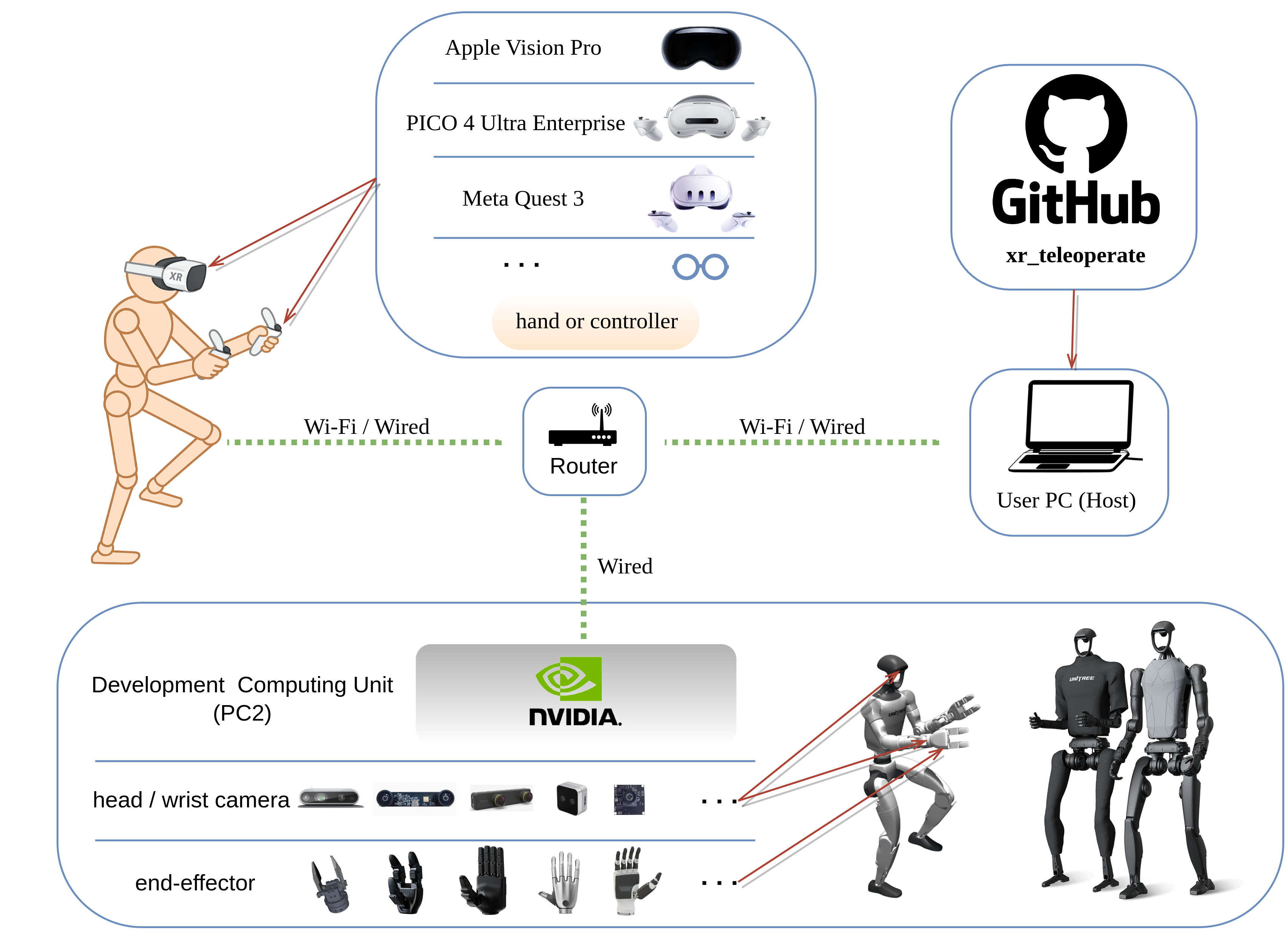
XR teleoperation is a hardware and networking stack: robot sensors, host machine, headset, image streaming, retargeting, and control paths. Source: Unitree XR Teleoperate repository.
Fourier ActionNet is useful because it makes the equipment concrete. The public project describes Fourier GR1-T1, GR1-T2, and GR2 humanoids, Fourier dexterous hands, an OAK-D W 97 wide first-person camera, Apple Vision Pro teleoperation, robot-side HDF5 files for action and state, and camera-side RGB/depth files with timestamps. It reports more than 30,000 teleoperated trajectories, about 140 hours, and a CC BY-NC-SA dataset license. The license limits commercial reuse, but the packaging is a good standard to compare against.
For a buyer, "teleoperated" is not enough detail. Ask what the operator saw, what they controlled, how commands were retargeted, what latency was present, whether haptic or force feedback existed, and whether failed attempts were included. A polished success-only teleop set can be less useful than a messier set that preserves corrections, retries, and recoverable failures.
Motion capture and human video are not the same thing
Human motion can help humanoid robots, but the capture method decides how much work remains before the data is robot-usable.
Optical motion capture and IMU suits can produce body trajectories with timing and kinematic structure. That can help with walking, reaching, squatting, balancing, carrying, and whole-body skill priors. HumanPlus, for example, uses AMASS human motion data, real-time RGB-based human motion estimation, a customized 33-DoF Unitree H1-based humanoid, and egocentric robot cameras as part of a pipeline for humanoid shadowing and behavior learning.
Human video is broader and cheaper. Ego-style video can show hands, objects, tasks, rooms, tools, and daily-life context at scale. But ordinary video usually lacks robot state, calibrated 3D object pose, action commands, force, tactile contact, and embodiment-compatible trajectories.
That difference is central to dataset buying. Human video can be useful for perception, task semantics, language grounding, and pretraining. Motion capture can be useful for body priors and retargeting. Neither is automatically humanoid policy data until it is connected to a robot body, action representation, and validation loop.
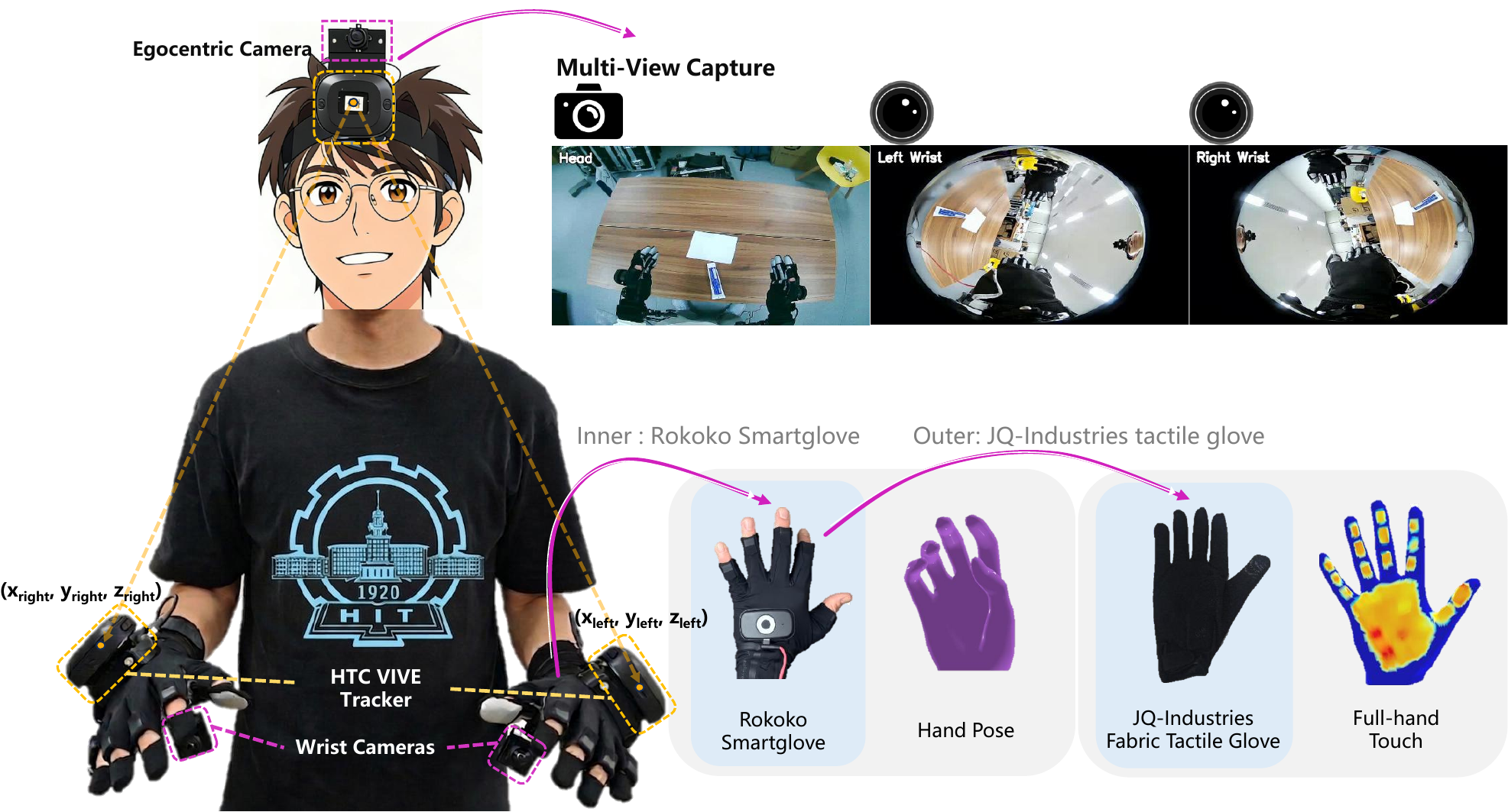
Human-worn capture can add hand pose, egocentric vision, wrist views, pressure signals, and motion capture, but it still needs retargeting before it becomes humanoid robot action data. Source: TouchAnything repository.
GRAIL's generation pipeline shows why this distinction matters. The project starts from known 3D assets and controlled scene context, uses video priors, then reconstructs and retargets trajectories for humanoid training. The asset and retargeting chain is not decoration. It is the provenance that turns media into robot data.
Force and tactile sensors capture what cameras miss
Cameras can show that a hand touched a cup. They often cannot show whether the grip was slipping, how pressure moved across the fingertips, whether a cloth snagged, or how much force was applied during insertion, wiping, lifting, or closing a drawer.
That is where force and tactile data become valuable. The equipment might include wrist force-torque sensors, fingertip tactile arrays, tactile skins, pressure carpets, instrumented grippers, or contact-rich end-effectors. Public research around humanoid visual-tactile-action datasets, bimanual tactile loco-manipulation, FreeTacMan, VTouch++, DexViTac, and GeorgiaTech's Lidar-Tactile dataset is a sign that this category is maturing.
Tactile data is not automatically a premium feature. It commands a premium when the task needs contact reasoning and when the stream is synchronized with video, actions, hand pose, and outcomes. For gross navigation, a tactile hand may not add much. For dexterous manipulation, slipping, wiping, folding, plugging, tool use, or fragile objects, it can be the difference between a video dataset and an interaction dataset.
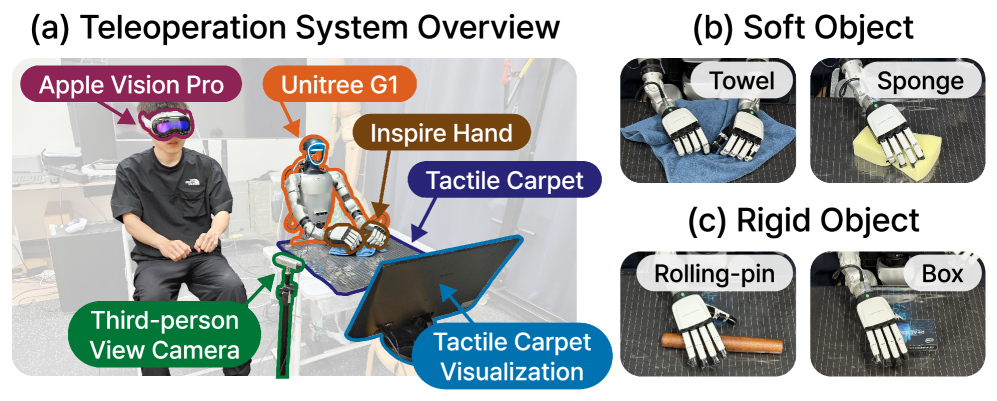
Contact-rich humanoid data needs equipment that sees and feels the interaction: head cameras, external RGB-D views, tactile hands, and pressure signals. Source: Humanoid Visual-Tactile-Action dataset paper.
Buyers should ask:
- Which surfaces or fingers were instrumented?
- What was the sampling rate and calibration process?
- Are tactile readings aligned with hand pose, action commands, and camera frames?
- Are contact events, slips, excessive force, or task failures annotated?
- Can the seller provide raw readings, normalized values, and schema documentation?
This is also a seller positioning point. If a dataset includes tactile or force channels, do not bury that detail under "multimodal data." Explain which contact problems the extra sensors make measurable.
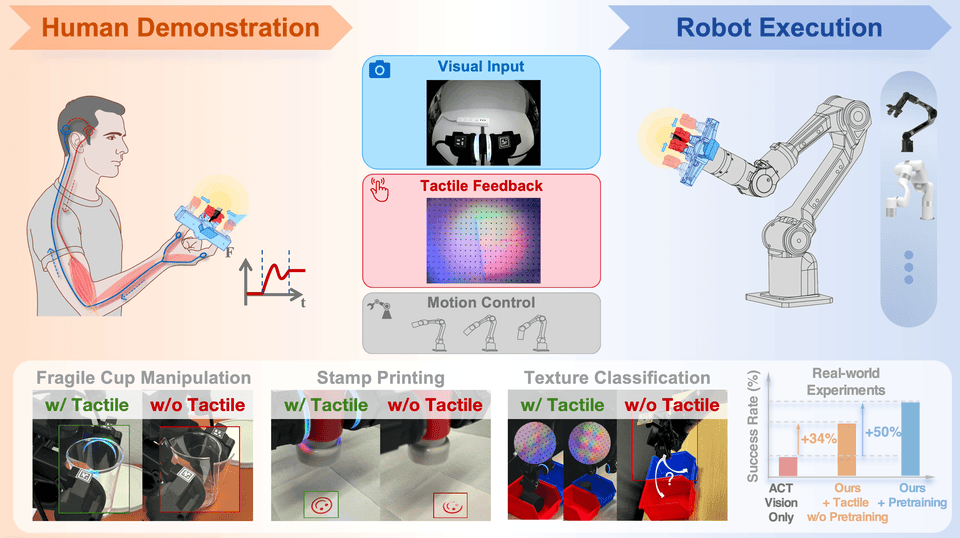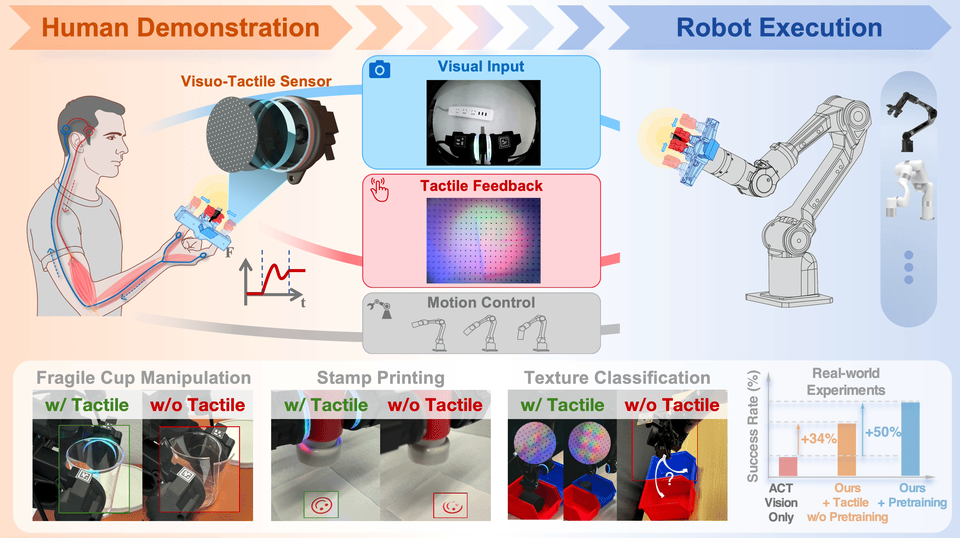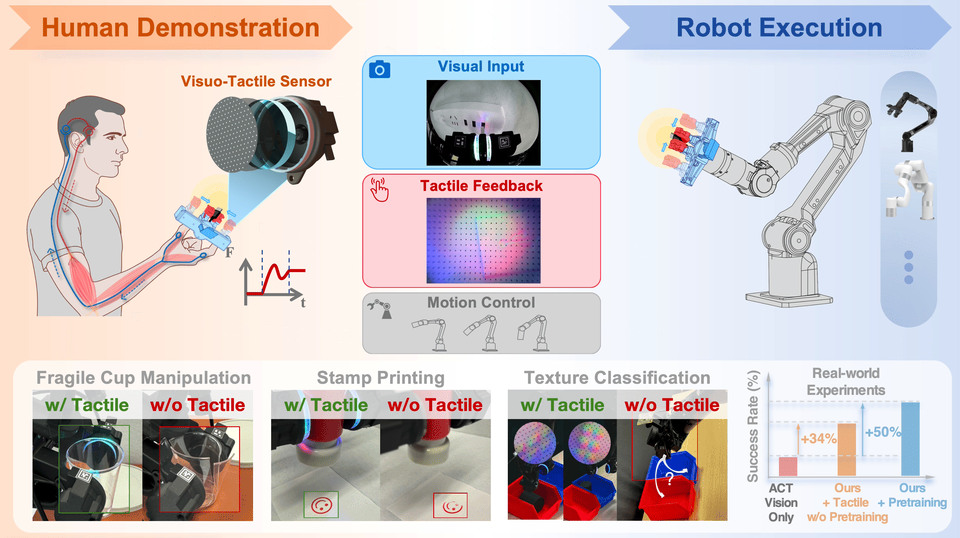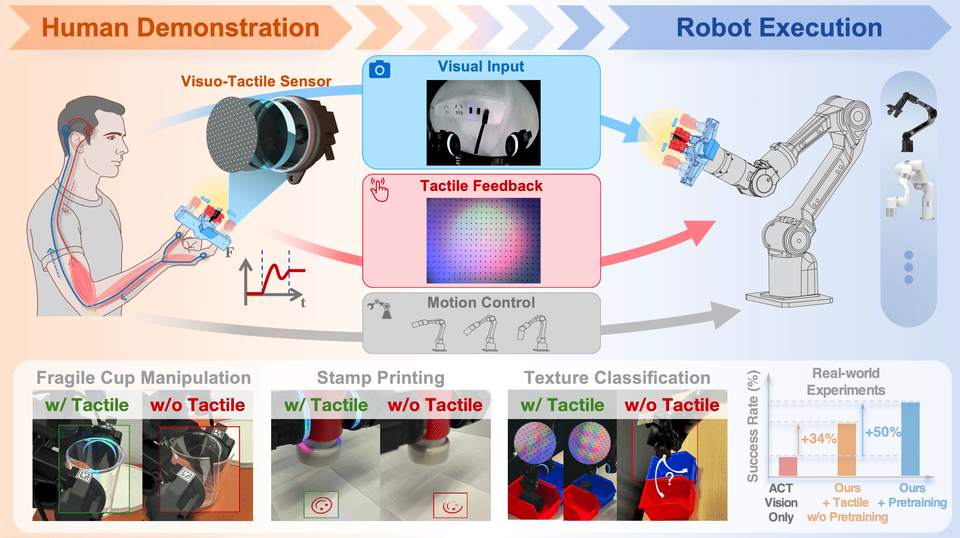
Not every useful contact rig is a full humanoid. FreeTacMan shows how a handheld visuo-tactile gripper can collect contact-rich data cheaply, while still needing embodiment review before reuse on a robot. Source: FreeTacMan project page.
Simulation rigs collect data too
Not every collection rig is physical. Simulation can generate robot-compatible observations, states, actions, object poses, segmentation, depth, and labels at a scale that would be painful to collect in the real world.
The strongest simulation data still has equipment-like provenance. Buyers should ask which simulator was used, what assets seeded the scenes, what robot model and controller were assumed, how physics parameters were chosen, what randomization was applied, and how generated episodes were filtered.
NVIDIA's GR00T-Mimic and GR00T-Dreams materials are useful examples because they frame synthetic data as part of a pipeline, not a magic source of unlimited demonstrations. NVIDIA's March 2025 technical blog describes an Isaac Lab and Omniverse workflow using Apple Vision Pro or space mouse teleoperation in simulation, subtask annotation, synthetic trajectory generation, and Cosmos Transfer for photorealistic variation. The blog reports 780,000 synthetic trajectories in 11 hours, equivalent to 6,500 hours of human demonstrations, and a 40% GR00T N1 performance improvement when combined with real data.

Synthetic collection still has equipment boundaries: devices, retargeters, robot interfaces, and data writers all shape the final dataset. Source: NVIDIA Isaac Teleop documentation.
For buyers, the key question is transfer evidence. Did synthetic data improve a real policy, benchmark, or evaluation? Where did it fail? What part of the training mix was real, and what part was generated? A synthetic dataset with documented assumptions and honest failure cases is easier to trust than a huge folder of plausible-looking clips.
Packaging is part of the equipment story
The best capture stack still loses value if the data is hard to load. A buyer needs files, metadata, and documentation that preserve the relationship between signals.
LeRobot has become important because it gives robotics teams a common way to store multimodal episodes: low-dimensional state and action data in Parquet, visual observations in MP4, metadata for schemas and episode offsets, task descriptions, statistics, and timestamps. Many recent humanoid datasets now use LeRobot or a LeRobot-like layout.
The details still matter. AgiBot World 2026 uses keys such as observation.images.top_head, hand_left, hand_right, and depth variants. Unitree-related G1 datasets often expose head and wrist cameras, end-effector state, hand state, current joint state, and action targets. GR00T's training format uses a LeRobot v2-compatible variant with extra modality metadata so concatenated state and action vectors can be mapped back into named signals.
That does not mean every dataset must use the same format. It does mean buyers should expect the same clarity:
- One episode timeline with aligned observations, state, actions, labels, and outcomes.
- Explicit modality names, units, coordinate frames, and sampling rates.
- Camera calibration files and sensor placement notes.
- Operator-interface metadata, including headset, glove, haptic, mocap, or leader-arm configuration.
- Retargeting details that explain how human or simulated motion became robot commands.
- Train, validation, and test split recommendations where relevant.
- Known missing data, excluded episodes, unsafe cases, and quality filters.
- Loader examples that let an engineer inspect a sample without reverse-engineering the capture rig.
This is where the buyer evaluation checklist becomes practical. Equipment diligence and file diligence are the same conversation. If a seller cannot explain how a camera frame lines up with a joint state and an action command, the dataset may be expensive to use no matter how impressive the demo reel looks.
A practical modality checklist
A good buyer review can start with this simple map:
- Vision: head, chest, wrist, external RGB, depth, segmentation, and camera calibration.
- Robot state: joint positions, velocities, torques, IMU, end-effector pose, gripper state, and body pose.
- Actions: commands sent to the robot, control frequency, action space, retargeting outputs, and policy-ready chunks.
- Contact: force-torque, tactile arrays, pressure maps, collisions, slips, and contact annotations.
- Human operation: operator viewpoint, control device, motion capture setup, latency, haptics, and intervention markers.
- Task context: language instructions, object identities, scene layout, success criteria, failure labels, retries, and reset states.
- Provenance: capture dates, locations, robot models, software versions, asset sources, consent, rights, and license terms.
The right bundle depends on the use case. A perception pretraining set may not need force data. A dexterous manipulation set probably does. A locomotion set needs body state, terrain context, and balance-relevant signals. A bimanual warehouse task needs object variation, hand state, synchronized camera views, and recovery attempts.
For open-data context, the guide to open humanoid robot datasets is useful because it shows the license spread behind many of these examples. Some of the best public equipment references are non-commercial datasets, which makes them excellent quality bars but not always usable training sources for a commercial product.
What buyers should ask before paying
Before negotiating price, ask for a sample episode and answer these questions with the engineering team that will use the data:
- Can we replay every modality on the same timeline?
- Does the robot embodiment match our target closely enough, or is retargeting required?
- Are sensor rates, coordinate frames, calibration, and missing data documented?
- Are action commands included, not only observations?
- Are failures, interventions, and recoveries included?
- Are rights clear for commercial model training, evaluation, and deployment?
- Can we load the data with the seller's documentation in less than a day?
That last question is blunt, but useful. If the data cannot be inspected quickly, integration cost will become part of the real price.
What sellers should make visible
For sellers, collection equipment is not back-office detail. It is part of the product.
A strong dataset listing should describe the capture stack in the first page of documentation: robot model, hands, sensors, cameras, teleoperation interface, timing, calibration, task families, environments, annotation layers, quality checks, rights, and sample files. If the dataset includes premium modalities such as tactile, force, motion capture, or high-quality retargeting, explain why those signals matter for the tasks being sold.
Do not oversell sensor count. A simple, well-synchronized rig can be more valuable than a heavy rig with unclear timing and missing calibration. The market will reward datasets that are specific, replayable, and honest about limitations.
Humanoids Data helps teams find and evaluate humanoid robotics datasets across motion, vision, teleoperation, simulation, tactile, and interaction data. If you need a dataset collected with a specific equipment stack, describe the target robot, modalities, and task in the buyer request form. If you have robotics data to list or license, make the rig, rights, and documentation clear in the seller submission form.