Humanoid robot data · 4 July 2026
NVIDIA SimFoundry and the Next Real-to-Sim Data Loop
TL;DR
SimFoundry is interesting because it treats real-to-sim as a data loop, not a rendering trick. A single video becomes a reconstructed scene, the scene becomes editable through digital cousins, and the resulting simulation is used to evaluate or train robot policies.
The claim to test is not whether the demos look good. It is whether SimFoundry scenes preserve policy ranking and transfer signals. The paper reports a 0.911 mean Pearson correlation across 7 tasks and 5 policy types, plus zero-shot transfer results on DROID and YAM setups.
The weak point is provenance. A reconstructed scene is only as trustworthy as its source capture, meshes, collision geometry, simulator configs, tuning logs, failed generations, real-robot validation, and rights chain. Without those files, the data product is just a confident-looking reconstruction.
Contents
- Introduction: the real-to-sim promise
- Main argument:
- Evidence to check:
- Implications and diligence:
- Conclusion: ask for the boring files
Introduction: the real-to-sim promise
NVIDIA Research's SimFoundry is a real-to-sim system from NVIDIA, Georgia Tech, Stanford, UT Austin, and the University of Toronto. The pitch is unusually concrete: give it a single real-world video, and it turns that scene into an interactive simulation environment for robot policy evaluation and training.
The signal is not the digital twin. It is the loop around it. SimFoundry reconstructs the scene, generates object and layout variants, trains or evaluates policies in simulation, then checks whether those results still mean anything on real robots.
For humanoid robot training data, that changes what "simulation data" can mean. The interesting unit is no longer a generic synthetic scene. It is a scene reconstructed from one real capture, expanded into task-relevant variants, and backed by a sim-to-real evaluation claim. More interesting. Also much easier to overclaim.
SimFoundry teaser video showing the real-to-sim-to-real loop from a reconstructed scene to policy training and evaluation. Source: NVIDIA Research SimFoundry project page.
What SimFoundry changes
SimFoundry is a modular real-to-sim pipeline that reconstructs interactive scenes from a raw RGB video, generates physics-ready object meshes, aligns them with a 3D Gaussian Splat background, and then expands the result into "digital cousins" across objects, scenes, and tasks. The paper was posted on arXiv on 2026-06-25.
The strongest reported result is not a single demo clip. Across 7 manipulation tasks and 5 policy architectures, the authors report that SimFoundry simulation evaluations predict real-world performance with a mean Pearson correlation of 0.911 and mean maximum ranking violation of 0.018. They also report policies trained on SimFoundry data transferring zero-shot to real DROID and YAM setups, with some tasks reaching 99% or 100% success in the paper's experiments.
I like the direction more than I expected to, mostly because the system treats scene generation, policy evaluation, and policy training as one loop. The weak version of synthetic robotics data is "we rendered more scenes." The stronger version is "we reconstructed a real scene, generated variations that preserve affordances, ran policies in the sim, and measured whether the sim ranked those policies like the real world did."
Still, a generated scene is not a dataset card. The video source, object meshes, physics properties, simulator configs, task specs, rejected generations, license chain, and real-robot validation matter as much as the rendered result. Without them, the pipeline is projecting confidence from a glossy diagram. Dangerous little product category.
From one video to a trainable scene
The paper describes three stages: Extraction, Generation, and Augmentation. Extraction starts from raw RGB video, selects a representative frame, estimates depth, builds a scene point cloud, segments foreground objects, and removes objects through image and depth inpainting until the foreground is decomposed.
Generation then creates the assets. Each object crop is upsampled, passed through a 2D-to-3D mesh model, aligned back into the scene, and given collision geometry through CoACD. The system assigns physical properties such as mass and friction through a scene-understanding model, resolves object penetrations in PyBullet, and exports sim-ready scenes to downstream simulators such as Isaac Lab.
That conversion is the hard part: from phone video to aligned meshes, collision geometry, object poses, task goals, and policy rollouts. Most teams can record a table, drawer, kitchen counter, or toy scene. Far fewer can turn that capture into a trainable robot environment without weeks of hand authoring.
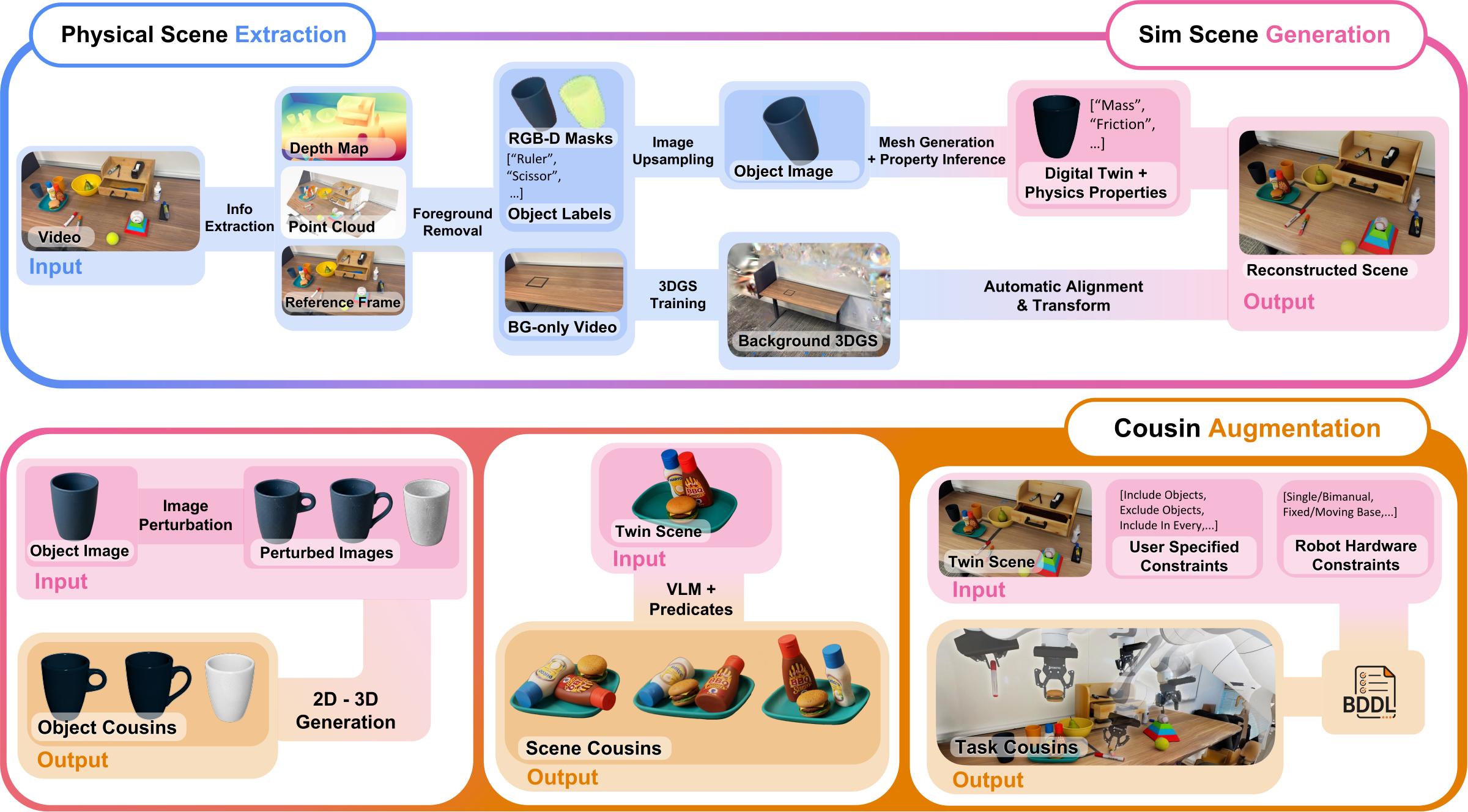
The SimFoundry pipeline: physical scene extraction, sim scene generation, and cousin augmentation. Source: NVIDIA Research SimFoundry project page.
The background step is also worth watching. SimFoundry can remove foreground objects, inpaint the background, train a depth-supervised 3D Gaussian Splat, and align that background with the foreground object meshes. The page describes the final scene as a hybrid: 3D Gaussian Splat background plus textured object meshes.
For simulation environments for robot training data, this is the direction I care about. The simulator is no longer only a physics engine. It is becoming a reconstruction system, asset generator, task generator, policy evaluator, and data-production tool in the same workflow.
Cousins are the data product
The phrase "digital twin" gets too much attention. A twin has value, but one reconstructed scene is still one scene. SimFoundry's harder-working idea is the "digital cousin": a variation that preserves the affordances of the real scene while changing the object instance, layout, or task.
The paper splits cousins into 3 axes. Object cousins change the object while preserving task function, such as turning one mug, drawer, or plate into plausible alternatives. Scene cousins change layout using semantic predicates like OnTop or RightOf, rather than random jitter. Task cousins ask what other feasible manipulation tasks the reconstructed scene can support.
That is the right mental model for synthetic data. The valuable question is not "how many scenes can I generate?" It is "which variations preserve the thing the robot has to learn?"
Task-cousin overview from the SimFoundry page. The data value is in generating new feasible interactions from a reconstructed scene, not just visual variants. Source: NVIDIA Research SimFoundry project page.
That is also where SimFoundry connects to the broader synthetic data generation question. Synthetic scenes earn their keep when they add coverage the real collection process cannot afford: unseen objects, different layouts, related tasks, edge cases, and controllable evaluation worlds.
The paper reports average task success improvements of 17%, 21%, and 40% when policies trained in simulation use object, scene, and task cousins respectively. I would not treat those percentages as a portable guarantee. I would treat them as evidence that the axes of variation are worth separating during evaluation.
The 0.911 correlation claim
SimFoundry's most important claim is evaluation correlation. The authors use SimFoundry environments to evaluate real-world robot policies in simulation, then compare those simulation results with real-world performance. The reported mean Pearson correlation is 0.911, with MMRV of 0.018, across 7 tasks and 5 policy types.
The task set matters. The paper says the experiments cover DROID with a single Franka arm and a bimanual YAM workcell, across short-horizon pick-and-place, articulated-object interaction, bimanual coordination, and long-horizon language following. The policies include pi0, pi0.5, GR00T N1.6, GR00T N1.7, and DreamZero.
That spread makes the result more credible than a one-task benchmark. It also gives the work a sharper test: does the synthetic evaluation preserve policy ranking, or does it only produce visually convincing rollouts?
Marker in Cup real-world rollout. Source: NVIDIA Research SimFoundry project page.
Marker in Cup SimFoundry rollout. Source: NVIDIA Research SimFoundry project page.
SimFoundry compares against PolaRiS, a real-to-sim evaluation framework for generalist robot policies. The SimFoundry paper reports a mean Pearson correlation more than 0.59 higher than PolaRiS under its comparison protocol. That is a serious claim, but the practical read is narrower: check whether the evaluation protocol matches the robot, policy family, cameras, task length, and success criteria.
One more detail I like: the authors report that sub-task evaluation increased mean Pearson score from 0.90 to 0.95. That matters commercially because failures in long-horizon tasks are rarely uniform. If a simulation can identify which subtask bottlenecks a policy, it can guide the next data collection run instead of just printing a final success rate.
Training transfer without the magic trick
The training results are the part most likely to be abused in sales copy, so read them carefully. The paper reports zero-shot sim-to-real transfer on both YAM and DROID. It mentions 99% success on Pot on Stove with YAM and 100% success on Stack Dishware with DROID in the reported setting.
That supports the case for SimFoundry-generated data. It does not prove that any single-video reconstruction can train any robot to do any task.
The co-training result is the more believable commercial pattern. On DROID, adding small amounts of real data improved results, including pi0.5 real-world success on Store Marker rising from 60% to 92%. That is the shape I expect to see in the market: synthetic scenes expand coverage, while real demonstrations keep the policy grounded in the actual robot, sensor, controller, and task mess.
The multi-task result carries a different message. The paper reconstructs a cluttered scene, generates tasks, fine-tunes pi0.5 variants, and evaluates on 13 generated-data tasks plus 7 held-out tasks. It reports pi0.5-FT reaching 29% success on held-out real tasks without task-specific demonstrations.
Twenty-nine percent is not a victory lap. It is a signal. For commercial use, an honest 29% held-out result is more valuable than a perfect demo reel with no denominator.
The 3-minute tuning detail
The reconstruction numbers deserve their own section because bad geometry can poison the whole real-to-sim loop. SimFoundry reports zero-shot F1 scores of 0.81 to 0.92 across 12 reconstruction scenes, with 3 minutes of per-object tuning improving those scores to 0.93 to 0.99. The paper also says objects are reconstructed at roughly 5 minutes per object on average.
That tradeoff is the point: automated enough to scale, but still able to accept targeted operator tuning when an object matters. I do not see the 3-minute tuning as a weakness. I see it as a reminder that robotics data quality often comes from small human interventions at the right place.

Wooden drawer twin and generated cousins. The question is whether the cousin preserves affordances, not whether the render looks nice in isolation. Source: NVIDIA Research SimFoundry project page.
The project page also compares SimFoundry against SAM3D and reports lower Chamfer distance and position error on easy, medium, and hard scenes. Helpful, but not sufficient. A low mesh error does not prove the drawer slides correctly, the cup has the right contact properties, or the policy will survive a camera calibration mismatch.
Diligence has to stay physical. Ask for collision geometry, articulated joints, physical parameters, alignment errors, simulator version, tuning logs, and examples of failed reconstructions. The rejected cases are not embarrassing. They are the map.
Provenance now includes the generator
For traditional robot datasets, provenance means who collected the data, which robot was used, what sensors were logged, how episodes were labeled, and what rights attach to the files. SimFoundry adds a second provenance chain: how the simulation was generated.
That chain includes the input video, selected frame, depth model, segmentation model, mesh generator, pose estimator, inpainting process, CoACD collision geometry, mass and friction assignment, PyBullet stabilization, Isaac Lab export, task generator, and any human tuning. The paper's modular design is good engineering, but it also means the generated dataset inherits every module's assumptions and failure modes.
Rights matter here too. The SimFoundry project page links the arXiv paper and project media, but I did not find a public repository or dataset license linked from the project page during this pass. That may change. For now, a commercial team should not assume that generated scenes, meshes, videos, or policy data are automatically licensable for model training.
This is the same trap covered in our guide to open humanoid robot datasets: the word "open" or "synthetic" does not settle commercial rights. You need the actual license chain.
What to request before trusting the data
If someone offers data generated with SimFoundry or a similar real-to-sim pipeline in 2026, I would ask for the following before trusting the dataset:
- The source capture: original video, capture device, camera intrinsics if known, scene date, and whether any objects were moved or removed.
- The generated assets: textured meshes, collision meshes, articulated joints, object poses, scale, mass, friction, and background representation.
- The generation config: model versions, simulator versions, seeds, PyBullet stabilization settings, Isaac Lab export settings, and human tuning notes.
- The task layer: goal definitions, success criteria, generated demonstrations, task-cousin prompts or predicates, and rejected task candidates.
- The policy evidence: real-vs-sim evaluation protocol, policy families tested, rollout counts, success metrics, sub-task results, and failure modes.
- The rights package: source asset rights, generated asset rights, redistribution rights, commercial model-training rights, and any third-party model restrictions.
- The embodiment fit: DROID, YAM, Franka, humanoid, hand, gripper, camera placement, control frequency, action representation, and retargeting assumptions.
The checklist overlaps with our guide to evaluating humanoid robot training data, but SimFoundry-style data adds one extra burden. You are not only evaluating captured episodes. You are evaluating the generator that produced them.
For teams packaging this as a dataset, the opportunity is documentation. A documented real-to-sim dataset can be much easier to diligence than a folder of robot videos. The winning package is not "unlimited synthetic data." The winning package is a reproducible generation recipe with examples, failures, rights, and proof that it helped a real policy.
Conclusion: ask for the boring files
SimFoundry points to a more practical version of real-to-sim-to-real robotics data. The market has spent years arguing about real data versus synthetic data. That was always too blunt. The better question is where each signal enters the loop.
Real captures ground the scene. Reconstruction turns the capture into assets. Digital cousins expand coverage. Simulation creates evaluation and training rollouts. Real robot trials test whether the loop survived contact with reality.
That is the data product I expect more teams to ask for: not generic synthetic scenes, but reconstructable, editable, replayable worlds tied to real deployment evidence.
The limit is equally clear. SimFoundry is a research system reported in a 2026 paper, not a license-ready marketplace listing by itself. If you are using or licensing data inspired by it, ask for the boring files. Meshes. Logs. Configs. Failure cases. Rights. The boring files are where the money is protected.
Humanoids Data helps teams find and evaluate humanoid robotics datasets across motion, vision, teleoperation, simulation, and interaction data. If you need data for humanoid robot learning, use the buyer request form. If you have robotics data to list or license, use the seller submission form.