Humanoid robot data · 23 June 2026
Synthetic Data Generation for Robot Training Data: Methods, Uses, Advantages, and Disadvantages
In this guide
- The short answer
- How synthetic data is generated:
- Where it is useful:
- Advantages of synthetic robot data
- Disadvantages and transfer risks
- Method comparison table
- What buyers should ask before trusting it
- What sellers should prepare
- The market implication for Humanoids Data
Synthetic data generation is the practice of creating robot training data with simulation, procedural scene tools, automated trajectory generation, synthetic labels, or generative models instead of collecting every episode directly on physical hardware.
For robotics, the useful tension is simple: real robot data is expensive because the world is physical, slow, risky, and messy. Synthetic data is attractive because the world can be copied, randomized, labeled, reset, and accelerated. The hard part is that a simulated grasp, footstep, camera frame, or bimanual handoff only helps a real robot if the generated data preserves the signals the model actually needs.
That makes synthetic data a powerful scaling layer, not a free replacement for real collection. It can fill gaps in a dataset, produce perfect labels, stress-test policies, generate unsafe edge cases, and stretch a small set of demonstrations into a larger training corpus. It can also create a false sense of coverage if the physics, sensors, embodiment, assets, controller, or license terms are poorly documented.
If you are new to the category, start with what humanoid robot training data is. For the simulator layer behind many of these workflows, the companion guide to simulation environments for robot training data compares Isaac Sim, MuJoCo, Genesis, Gazebo, ManiSkill, and the wider stack. This article focuses on the data-generation methods themselves: how synthetic data is made, where it helps, where it fails, and what buyers should ask before treating it as training-ready.
MimicGen shows the central promise of synthetic robot demonstrations: use a source human trajectory, adapt it to a new scene, and keep the generated episode only when the task succeeds. Source: MimicGen project page.
The short answer
Synthetic robot training data is most useful when it does one of five jobs.
It can create labeled perception data, such as RGB, depth, segmentation, bounding boxes, optical flow, object pose, and camera parameters. It can randomize the world so a model sees many lights, textures, object placements, camera views, masses, frictions, and distractors before deployment. It can generate demonstrations from a smaller seed set, as MimicGen does for manipulation tasks and DexMimicGen extends to bimanual dexterous manipulation. It can build large procedural environments, such as RoboCasa kitchens, where tasks, assets, layouts, and textures vary systematically. It can also augment real observations with image or video generative models, as GenAug does for tabletop manipulation.
The value is not "synthetic versus real." The value is the mix. Synthetic data buys scale, labels, controllability, and coverage. Real data grounds the dataset in the true robot, true sensors, true controller, true contact, true latency, and true deployment mess.
For humanoid teams, that distinction is more than academic. A humanoid is not only seeing the world. It is balancing, reaching, walking, turning its head, coordinating two arms, using hands or grippers, and managing contact with objects, people, floors, tools, doors, and furniture. Synthetic data becomes commercially valuable when it keeps those relationships aligned on one episode timeline: observation, robot state, action, contact, task context, success, failure, and provenance.
Domain randomization
Domain randomization is the method most people think of first. Instead of trying to make one simulator perfectly match the real world, you deliberately vary the simulator so the model learns to handle a wide distribution of worlds.
The classic visual version was described in Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. The paper randomized simulated camera images with camera positions, lighting, object positions, and non-realistic textures, then transferred an object detector to real robot grasping. The careful claim is not that domain randomization always solves sim-to-real. The claim is that enough simulated variability can help a model treat the real world as another point inside the training distribution.
In robot training data, randomization can target:
- Visual appearance: texture, lighting, camera pose, background, object color, clutter, glare, blur, shadows, and sensor noise.
- Physical parameters: object mass, friction, restitution, joint damping, motor strength, control latency, floor condition, and contact stiffness.
- Task state: object placement, initial robot pose, goal position, distractor objects, subtask order, and failure condition.
- Sensor outputs: RGB, depth, lidar, IMU, tactile, force, segmentation, and synthetic noise models.
NVIDIA Isaac Sim is a practical example of this workflow. NVIDIA describes Isaac Sim as a framework for robotics simulation, testing, and synthetic data generation in physically based virtual environments, with pipelines for randomizing lighting, reflections, color, and asset positions. Its Replicator documentation focuses on synthetic data generation workflows for robotics, including domain randomization, sensor simulation, annotators, and writers.
The buyer question is not whether randomization was used. It is what was randomized, why those ranges were chosen, and whether the ranges cover the deployment world without destroying the task. A policy trained on extreme randomization can become robust to nuisance variation. It can also learn a weak behavior if the randomization breaks the physical structure of the task.
Synthetic demonstrations from seed episodes
Synthetic demonstrations are generated robot episodes that look like training demonstrations: observation in, action out, task result at the end. They are especially important for imitation learning and vision-language-action policies because they can multiply a small set of human demonstrations.
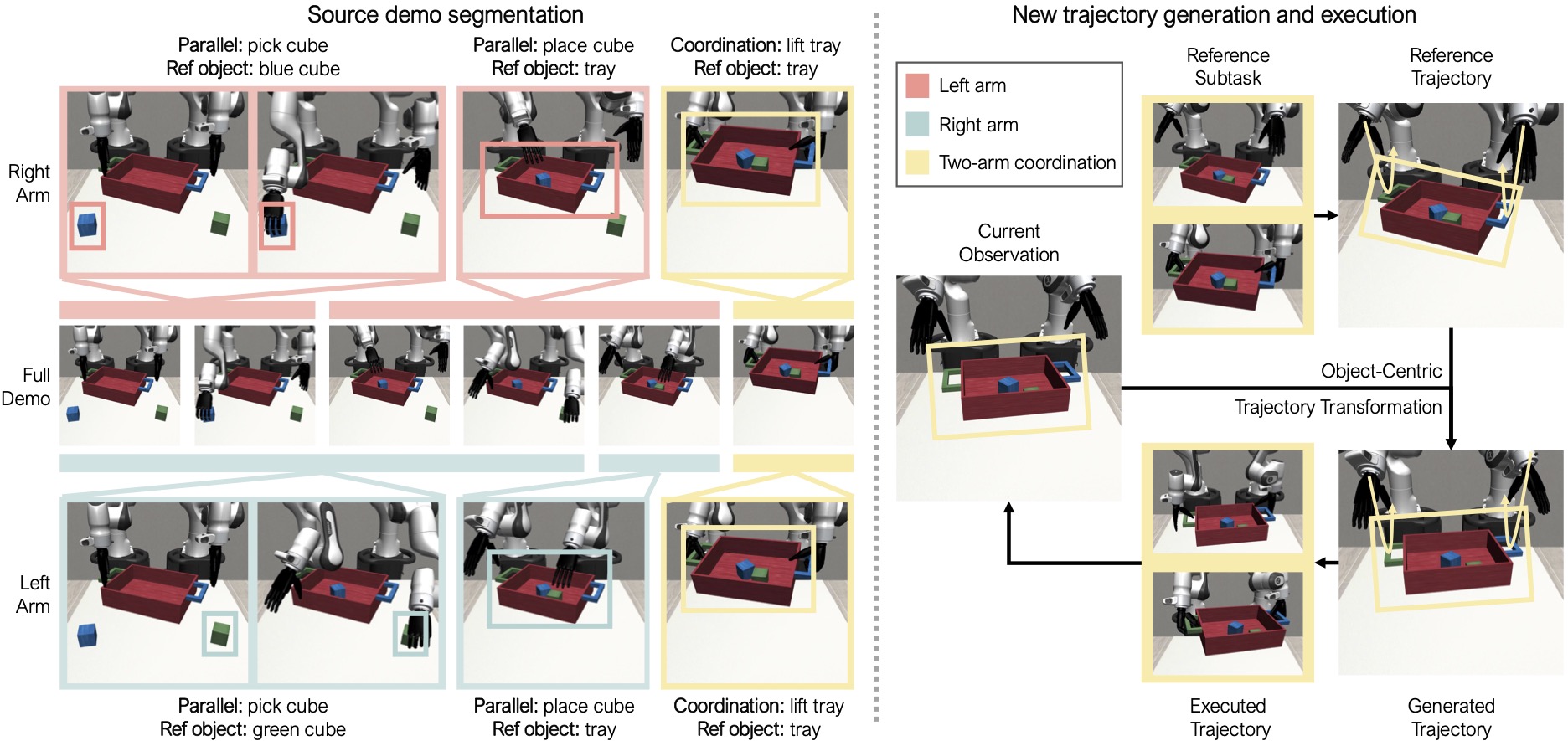
MimicGen is the clean reference. The project reports generating more than 50,000 demonstrations from fewer than 200 human demonstrations across 18 tasks, multiple simulators, and the real world. The method does not generate useful behavior from nothing. It starts from source human demonstrations, decomposes behavior into object-centric segments, transforms those segments into new scene configurations, executes them in simulation, and keeps successful rollouts.
For humanoids and bimanual robots, DexMimicGen is more directly relevant. Its project page reports more than 20,000 generated demonstrations from 60 source demonstrations across 9 tasks, and the paper frames the work around bimanual dexterous manipulation. The method matters because humanoid manipulation is not just "more arms." It introduces coordination, sequential dependencies, hand control, embodiment constraints, and real-to-sim-to-real transfer questions.
DexMimicGen's pipeline is useful diligence evidence because it shows where human demonstrations, simulation generation, policy training, and real-world deployment sit in the loop. Source: DexMimicGen project page.
For commercial training data, synthetic demonstrations should be evaluated as episodes, not animations. A buyer should be able to inspect the action space, controller, robot state, task success criteria, rejected failures, simulator version, robot model, object poses, and whether generated trajectories were replayed on real hardware or only tested in simulation.
The strongest sellers will also disclose the seed data. If 10 human demonstrations generated 1,000 synthetic episodes, the seed episodes still define the behavior distribution. Synthetic scale can amplify a good seed set. It can also amplify a narrow, biased, or poorly documented one.
Procedural scenes, assets, and tasks
Procedural generation creates many scenes, layouts, assets, tasks, or object arrangements from rules, templates, repositories, scans, or generative tools. It is useful when the bottleneck is environmental diversity rather than only action volume.
RoboCasa is a strong robotics example because it combines simulated kitchen environments, tasks, human demonstrations, and synthetic demonstrations. Its documentation says RoboCasa offers more than 2,200 hours of demonstration data across human teleoperation data and synthetic data. The pretraining split includes 482 hours of human data and 1,615 hours generated via MimicGen, with the synthetic data spanning 60 atomic tasks at about 10,000 demonstrations per task. The project also uses many kitchen scenes, object assets, textures, and task definitions to make household manipulation less narrow.
RoboCasa's scene collage shows why procedural environments matter: synthetic data is often about expanding the distribution of rooms, fixtures, objects, and layouts, not only rendering more frames. Source: RoboCasa project page.
This kind of data is useful for navigation, household manipulation, object search, mobile manipulation, evaluation, and pretraining. It is less useful when a buyer needs exact coverage of a factory, hospital, warehouse, lab, or home environment that the procedural generator did not represent.
For humanoid buyers, procedural scenes create one extra diligence question: can the simulated body actually act in those scenes? A kitchen scene that works for a single mobile manipulator may not support a humanoid's height, reach, base motion, foot placement, self-collision constraints, head cameras, or hand geometry. Scene diversity is valuable only when the embodiment can use it.
Synthetic labels for perception
Synthetic labels are one of the least controversial uses of synthetic data. A simulator knows where the object is, which pixels belong to it, how far each pixel is from the camera, where the optical flow points, what class an asset carries, and which collision occurred. In the real world, each of those labels can be expensive, noisy, or impossible to annotate at scale.
Kubric is a useful reference outside pure robot policy learning. The project describes itself as a pipeline for creating semi-realistic synthetic multi-object videos with rich annotations such as instance segmentation masks, depth maps, and optical flow. The Kubric paper adds that it combines Blender rendering and PyBullet physics, exports rich ground-truth annotations, and was designed to make reusable synthetic dataset generation less fragmented.
For robotics, synthetic labels can support:
- Object detection and segmentation for warehouses, homes, labs, factories, tools, packages, pallets, and grippers.
- Depth, pose, optical flow, normals, and object state for perception and scene understanding.
- Contact, collision, success/failure, and task-state labels when the simulator tracks those events.
- Dataset debugging, because labels can reveal whether a camera, object, or scene randomizer is producing impossible examples.
The limitation is familiar: perfect labels on the wrong distribution are still wrong training data. A simulator can label every pixel of a glossy mug, but if the mug mesh, material, lighting, camera noise, occlusion, and grasp context do not match the real task, the model may learn the wrong invariances.
Generative augmentation and real-to-sim loops
Generative augmentation uses image, video, 3D, or world models to vary existing data. It can change textures, backgrounds, objects, distractors, or visual style while trying to preserve the robot-relevant structure of the episode.
GenAug is a concrete example. The project uses pretrained image-text generative models to create semantically meaningful augmentations for tabletop manipulation. Its project page reports a 40% improvement in generalization to novel scenes and objects in the tested setting, and describes augmenting a small set of demonstrations with new environments, distractors, textures, object classes, tables, and backgrounds.
This is appealing because many real robot datasets are visually narrow. A team may have good actions and state from one lab setup, but too little variation in objects, surfaces, backgrounds, or clutter. Generative augmentation can widen the visual distribution without recollecting every episode.
It also creates a subtle risk. If the image changes but the action labels, contact, object geometry, depth, or success condition no longer match, the dataset can become physically inconsistent. That is why generative augmentation is safest when it is constrained by masks, depth, simulation state, digital twins, or validation checks, and riskiest when it only produces attractive images.
Real-to-sim loops go the other direction. A team captures a real scene, robot, object, or demonstration, builds a digital twin, generates more variants in simulation, and then checks transfer back on hardware. NVIDIA's Isaac Sim materials now explicitly discuss ingesting CAD, URDF, real-world captures, teleoperation, OpenUSD scenes, and synthetic data pipelines. In the humanoid category, our analysis of NVIDIA GRAIL's synthetic humanoid data pipeline shows why real-to-sim provenance matters: generated motion is much easier to trust when the data loop includes source assets, retargeting, simulation, and real-robot validation rather than a loose pile of videos.
RoboCasa uses AI-generated textures as one route to scene diversity. For buyers, the useful question is whether visual variation remains physically and legally usable for the intended training run. Source: RoboCasa project page.
Perception, labels, and rare cases
The most straightforward use case is perception. Synthetic data can create thousands or millions of labeled views of objects, bins, shelves, tools, doors, stairs, pallets, packages, fixtures, or hazards without paying people to label every frame.
It is especially useful when:
- Real labels are expensive, such as segmentation masks, depth, 6D pose, optical flow, and contact timing.
- Rare cases matter, such as dropped objects, blocked aisles, unusual lighting, spill scenarios, occlusions, or near-collisions.
- Privacy or safety makes real collection hard, such as homes, hospitals, human interaction, or unsafe robot failures.
- The team needs balanced data for an event that real logs rarely contain.
The catch is that perception data often looks better than it transfers. Synthetic images can be visually impressive while still missing lens artifacts, motion blur, bad calibration, sensor compression, worn objects, transparent materials, reflective surfaces, dust, clutter, and awkward human environments. Synthetic perception data should be paired with real validation images and clear domain-gap testing.
Imitation learning and policy pretraining
Synthetic demonstrations matter when a model needs actions, not only labels. Imitation learning, diffusion policies, behavior cloning, and vision-language-action models often need aligned observation-action episodes. That makes the data modalities for robot training important: video, state, actions, contact, language, task context, and provenance should remain synchronized.
The best use is usually pretraining or augmentation. A team might collect a smaller number of high-quality real or teleoperated demonstrations, generate synthetic variants, train a policy on the larger mix, then validate and fine-tune on hardware. MimicGen, DexMimicGen, and RoboCasa all fit this pattern in different ways.
For humanoids, policy data should be reviewed for whole-body fit. A synthetic manipulation episode may include good hand motion but ignore balance, torso pose, locomotion, head-camera motion, or foot placement. It may train a useful arm policy while still being weak humanoid data. That is acceptable if the seller says so. It is dangerous if the data is marketed as whole-body humanoid training data without whole-body evidence.
Reinforcement learning, evaluation, and safety testing
Simulation can run resets, failures, and reward-driven rollouts at a scale physical hardware cannot match. That makes synthetic data useful for reinforcement learning, benchmark evaluation, regression testing, and safety checks.
High-throughput physics tools such as MuJoCo, Isaac Lab, ManiSkill, Genesis, Newton, and other frameworks can sample many variations of a task. A team can test whether a policy handles different object poses, masses, perturbations, or lighting. It can evaluate a new controller before the robot is allowed near expensive hardware or people.
The most valuable outputs are not always training episodes. Sometimes they are evaluation artifacts: seeded worlds, failure cases, replayable logs, contact traces, simulator state, and policy comparisons. For commercial buyers, that is still data. A repeatable synthetic evaluation suite can be worth licensing if it matches the target task and catches failures before hardware time.
Advantages of synthetic robot data
Synthetic data has real advantages when it is honestly scoped.
First, it reduces marginal collection cost. Once the simulator, assets, and generation logic exist, another thousand scene variants or rollouts can be cheaper than another thousand real robot episodes.
Second, it produces labels that are hard to get in the real world. Pixel masks, object poses, depth, optical flow, collision events, and state labels can be exported directly from the simulator.
Third, it improves coverage. Teams can generate rare events, unsafe cases, long-tail object arrangements, lighting variation, camera variation, and failure examples that are too risky or slow to collect physically.
Fourth, it improves reproducibility. A synthetic dataset can ship with seeds, simulator versions, scene files, robot models, assets, and replay scripts. That makes the dataset easier to audit than a folder of unlabeled real videos.
Fifth, it protects hardware. Reinforcement learning exploration, collision-heavy tests, and bad early policies are cheaper in simulation than on a real humanoid.
Sixth, it can reduce privacy and consent exposure. A warehouse or home-like simulation may avoid recording real workers, customers, homes, faces, or private spaces. That does not remove licensing diligence, because assets and generative outputs still have rights, but it changes the risk profile.
Disadvantages and transfer risks
The biggest disadvantage is the sim-to-real gap. Simulators simplify contact, friction, deformable objects, lighting, cameras, actuator dynamics, latency, wear, backlash, compliance, fluids, cables, cloth, humans, clutter, and edge cases. A dataset can be perfectly labeled and still teach a behavior that fails on hardware.
The second risk is embodiment mismatch. A dataset generated for one robot, hand, gripper, camera, controller, or action space may not map cleanly to another. For humanoids, this includes body dimensions, joint limits, balance constraints, hand kinematics, camera placement, control frequency, and whether the torso or legs were modeled at all. The guide to open-source humanoid robot hands is a good reminder that even hand geometry can change what a grasp dataset means.
The third risk is asset and license ambiguity. Synthetic does not mean rights-free. CAD models, scanned spaces, textures, 3D assets, simulator components, generated media, and source demonstrations may all carry license restrictions. Our guide to open humanoid robot datasets covers the same pattern in public datasets: commercial use is decided by the actual license chain, not by the word "open" or "synthetic."
The fourth risk is synthetic monoculture. If every episode comes from the same generator, the same task template, the same success filter, and the same simulator assumptions, scale can hide narrowness. A million generated episodes may still cover one worldview.
The fifth risk is filtered failure. Many generation systems keep successful rollouts and discard failures. That can be right for imitation learning, but it can also remove exactly the slips, drops, collisions, recoveries, and interventions a real robot needs to learn from.
Method comparison table
| Method | Best fit | Strengths | Watch-outs |
|---|---|---|---|
| Domain randomization | Robust perception, sim-to-real pretraining, nuisance variation. | Cheap variation in lighting, textures, poses, physics, and sensors. | Bad ranges can create unrealistic tasks or miss the real deployment distribution. |
| Synthetic demonstrations | Imitation learning, manipulation, bimanual tasks, policy pretraining. | Turns a smaller seed set into many aligned observation-action episodes. | Seed quality, success filtering, controller assumptions, and hardware transfer need evidence. |
| Procedural environments | Navigation, household tasks, mobile manipulation, evaluation worlds. | Expands scene, object, layout, and task coverage systematically. | Scene diversity does not guarantee embodiment fit or realistic contact. |
| Synthetic labels | Detection, segmentation, pose, depth, optical flow, state labels. | Exports labels that are expensive or impossible to annotate by hand. | Perfect labels on the wrong assets, cameras, or materials can still transfer poorly. |
| Generative augmentation | Visual diversity around limited real demonstrations. | Adds objects, textures, backgrounds, and distractors without full recollection. | Can break physical consistency between images, depth, actions, and outcomes. |
| Real-to-sim loops | Digital twins, hardware-specific validation, targeted dataset expansion. | Anchors simulation to real scenes, real robots, or real demonstrations. | Requires calibration, asset provenance, versioning, and real-world replay evidence. |
What buyers should ask before trusting it
Synthetic data diligence should be more specific than "which simulator did you use?"
Start with provenance:
- Which simulator, renderer, physics engine, robot model, asset library, and generator version produced the data?
- Were the episodes scripted, motion-planned, teleoperated, policy-generated, MimicGen-style, domain-randomized, or generatively augmented?
- What real demonstrations, scans, CAD files, textures, or third-party assets seeded the generation?
- Which license terms apply to the generated data, source assets, simulator components, and seed demonstrations?
Then inspect technical fit:
- What robot embodiment, hand or gripper, camera placement, controller, action space, and control frequency are represented?
- Are RGB, depth, state, actions, contact, labels, language, and outcomes aligned on one timeline?
- Which labels are simulator-native, and which were inferred later?
- Were failed rollouts retained, filtered, or summarized?
- Can a sample episode be replayed from source files?
Finally, ask for transfer evidence:
- Has the dataset improved a real robot policy, perception model, benchmark, or evaluation result?
- Was transfer measured on the same embodiment and task family the buyer cares about?
- What real validation set was used?
- Where does the synthetic data underperform real data?
- What should the buyer not use it for?
That last question is underrated. A seller who can explain where the synthetic data should not be used is usually closer to having a real data product.
What sellers should prepare
Synthetic dataset sellers should package the generator, not only the generated files.
Prepare:
- A dataset summary that separates real, teleoperated, simulated, generated, augmented, and filtered episodes.
- A generation card with simulator versions, randomization ranges, task definitions, success criteria, asset sources, seeds, and validation notes.
- A schema that documents observations, state, actions, labels, units, timestamps, coordinate frames, and missing fields.
- Example replay scripts or videos for representative successful and failed episodes.
- A license packet for source assets, generated data, simulator terms, human demonstrations, and commercial training rights.
- A transfer report that says what was validated on hardware, what was only validated in simulation, and what remains unknown.
For buyers who already use LeRobot-style workflows, packaging matters too. A synthetic dataset in a standard episode format is easier to inspect, but format alone does not prove quality. The buyer evaluation checklist still applies: embodiment fit, task coverage, synchronization, provenance, rights, and delivery quality decide whether the data can be used.
The market implication for Humanoids Data
Synthetic data generation is changing the robotics data market because it shifts value away from raw volume alone. "One million synthetic episodes" is not a useful claim unless a buyer knows where the episodes came from, what they preserve, what they randomize, what they filter out, and whether they transfer.
The sellers with the strongest position will not be the ones with the prettiest simulated videos. They will be the ones who can combine synthetic scale with real grounding: a clear source demonstration set, a documented simulator, legally usable assets, replayable episodes, failure coverage, and validation against real robot tasks.
For buyers, synthetic data is worth considering when it fills a named gap: rare cases, labels, pretraining coverage, unsafe scenarios, or evaluation worlds. It is risky when it is used to hide the absence of real-world evidence.
Humanoids Data helps robotics teams find datasets with the right mix of real, synthetic, teleoperated, simulated, and interaction data. If you need robot training data for a specific embodiment or task, use the buyer request form. If you have synthetic or real robotics datasets to license, prepare the provenance, rights, and validation notes clearly and submit them through the seller submission form.